内存泄漏的在线排查
潘忠显 / 2020-12-01
本文首先介绍在线排查内存泄露的通用步骤,然后介绍三个线上内存泄露问题的排查案例,最后介绍内存相关知识、指令选项说明,并对常见疑问进行解释。
一、在线排查内存泄漏的步骤
想到内存泄漏问题的排查,很多开发会想到使用 Valgrind。使用 Valgrind 有几个局限:
- 需要安装 Valgrind
- 需要启停服务进程
- 影响服务进程性能
- 依赖于测试用例覆盖到 BUG 分支
由于这些原因,线上内存泄露问题并不适合用 Valgrind 来排查。相反,利用 top、pmap 等命令,以及 GDB(包括gcore脚本)、Vim 等工具排查,会更灵活,更直接。
使用这些工具和指令排查基本步骤包括:
- 通过
top找到内存泄露的进程 - 通过
pmap找到内存泄露的地址及范围 - 通过
gcore对进程内存进行快照 - 通过
gdb加载内存信息 - 通过
dump binary导出泄露内存的内容 - 通过
vim查看内存内容 - 根据内存中的内容,锁定对应的代码段,进行排查修复
二、单线程案例
联调环境一台机器的应用程序使用的Memory usage (RES) 使用超过 1G。经确认,线上环境没有内存明显增长的情况出现。

通过TNM查看机器情况(请忽略中间的红线突起):
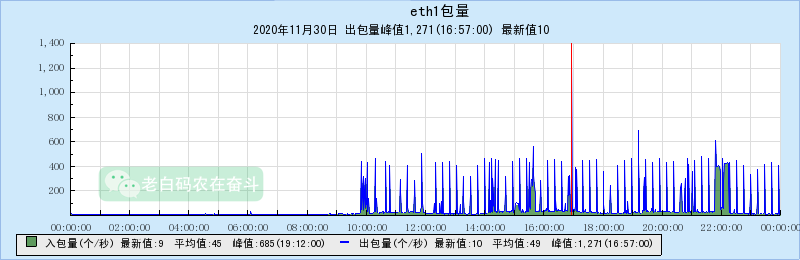
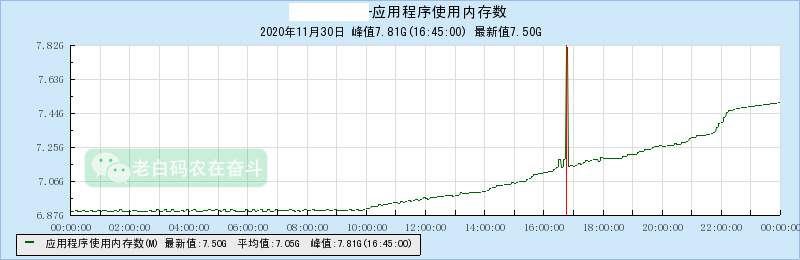
通过上边两个曲线可以直观的看出:
- 从10点开始,从某来源不断有请求发过来,响应这些请求的时候,应用程序使用的内存增加
- 请求量越大,内存上涨越明显,比如在22点左右请求持续,内存增长斜率变大
基本可以确定,因为联调环境的某些持续的异常请求,走到了程序某些异常处理分支,而这些分支中可能没有正确的释放内存。
因为该机器上只有一个主要进程,可以直接跳过定位哪个进程的内存泄露的过程
1. 定位内存泄露的地址范围
首先使用 pmap 加 {pid} 的方式,查看内存映射:
pmap -x 8704 # `-x`表示要显示扩展信息
结果如下:
8704: ./spp_worker ./../etc/spp_worker1.xml
Address Kbytes RSS Dirty Mode Mapping
0000000000400000 640 640 0 r-x-- spp_worker
00000000005a0000 12 12 8 rw--- spp_worker
00000000005a3000 2252 196 196 rw--- [ anon ]
0000000001f19000 132 132 132 rw--- [ anon ]
0000000001f3a000 1110656 1109196 1109196 rw--- [ anon ] *****
00007f2c90000000 56896 56896 56896 rw--- [ anon ]
...
通过虚拟内存地址,我们可以看出,这是一个 64 位进程的地址,因为 32 位进程地址是从 0 到 0xffffffff (4G),两者的范围不同,详见 #背景知识 – X86-64bit Linux内存布局
通过 pmap 的结果,我们已经找到了最大有占用 1G 多的一个连续的块:
0000000001f3a000 1110656 1109196 1109196 rw--- [ anon ]
根据地址可以看出这块大内存是在堆上,也就是可能我们 new 出来的对象没有 delete 掉。
2. 导出内存中的内容
首先要产生 core dump 文件,可以通过man core 指令查看对 core dump 文件的介绍,它包含有进程在某时刻的进程内存情况。
以下指令会产生文件 core 文件,并命名为"core.8704":
gcore 8704
使用 GDB 关联 bin 文件和 core dump 文件:
gdb spp_worker core.8704
通过 info proc 的 GDB 指令,查看内存映射情况:
(gdb) info proc mappings
process 8704
cmdline = './spp_worker'
cwd = '/xxxxxx/profile_svr/bin'
exe = '/xxxxxx/profile_svr/bin/spp_worker'
Mapped address spaces:
Start Addr End Addr Size Offset objfile
0x400000 0x4a0000 0xa0000 0 spp_worker
0x5a0000 0x5a3000 0x3000 0xa0000 spp_worker
0x5a3000 0x7d6000 0x233000 0
0x1f19000 0x1f3a000 0x21000 0 [heap]
0x1f3a000 0x4611a000 0x441e0000 0 [heap]
0x7f2c90000000 0x7f2c93790000 0x3790000 0
通过 GDB 的 dump 指令,将内存导出到文件,之后通过 Vim 进行查看。
因为内存已经涨的很多了,可以只 dump 出其中的一部分,而不用将 1G 多都 dump 出来。比如这里从起始位置偏移 0x20000000,即dump出 512M:
(gdb) dump binary memory result.bin 0x1f3a000 0x21f3a000
du -sh result.bin
512M result.bin
3. 分析内存内容
直接使用 Vim 打开导出的二进制文件,可以看到里边有大量的请求信息,并且没有返回信息。
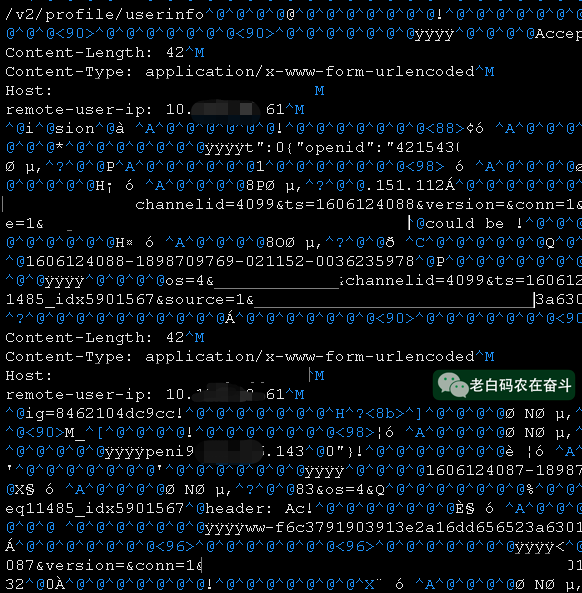
为了确认这块内存中具体的有多少请求,可以直接使用 grep 指令,查找并计数:
grep -a -c -P "application/x-www-form-urlencoded" result.bin
339755
512M 字节的内容有339755个HTTP请求,平均一个请求占用1500字节左右,基本可以确定是请求结构创建了而没有delete。
4. 定位内存泄露的代码
检查 service.cpp 中的 spp_handle_process 函数中有创建了 CommItopReq,其中一个分支是检查了请求中 channel_id 非法之后,会直接退出,没有 delete 指针。
extern "C" int spp_handle_process(unsigned flow, void *arg1, void *arg2) {
// ...
itop_common::CommItopReq *common_itop_req_ptr = new itop_common::CommItopReq;
if (common_itop_req_ptr == NULL) {
printf("create CommItopReq error.\n");
return -1;
}
// ...
if (!validate(common_itop_req_ptr->channelid())) {
printf("invalid channelid in req.\n");
return -1;
}
公司同事指出,上边代码的错误:如果直接 new 失败,是会抛异常,而不是指针为空。
这里使用 new 而不能直接声明变量的原因是:使用了 SPP 框架,在出了spp_handle_process函数作用域后,仍然会用到这个对象。
再去bin中确认,发现内存中大量遗留的请求是 channelid=4099 一个未配置的渠道ID:
grep -o -P -a "channelid=\d*" result.bin| sort | uniq -c | sort -nr
339796 channelid=4099
59 channelid=
改进方法
- 认真检查每个分支,return之前要delete掉出创建的对象
- 项目代码升级C++11或更高版本,使用智能指针管理内存
三、多线程案例
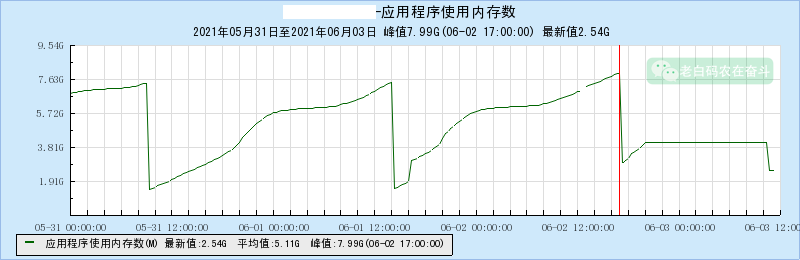
1. 定位哪个进程的内存泄露
用 top 命令,然后 shift + m 按照内存排序,找到 %MEM 最高(或上升最快)的进程:

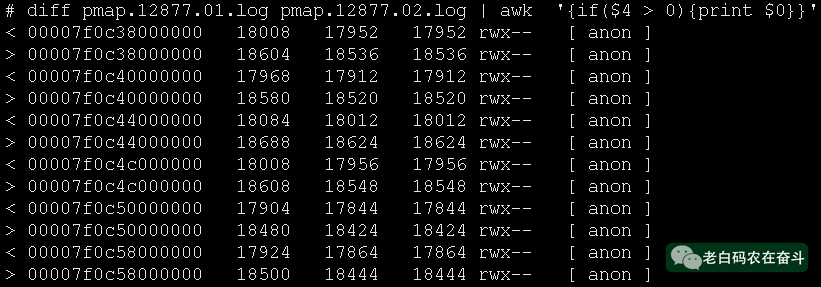
2. 定位内存泄露的地址范围
通过 pmap -x -p ${pid} 的方式可以查看内存情况:
- 内存是持续泄露,通过隔段时间,进行两次
pmap记录内存使用情况 - 物理内存占用明显增加,只需看
RSS一列大于 0 的情况 - 通过下图可以发现有 6 处位置有明显的物理内存增加
3. 定位内存泄露的线程
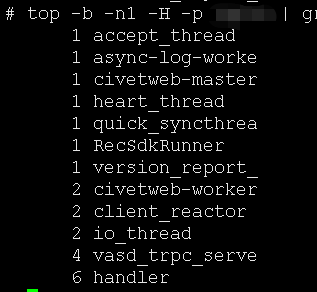
因为有 6 个不同的地址内存明显增加,很可能是在 6 个并发相同逻辑的线程造成的,直接 top 去查看有没有并发是 6 的线程。
top -b -n1 -H -p 94834 | grep -P "^\s*[0-9]+" | awk '{print $NF}'| sort | uniq -c | sort -n
发现只有 handler 线程是 6 个:
至此,找到了具体的线程,但是仍然还不知道具体的代码位置。

4. 导出并分析内存中的内容
根据之前的介绍,要分析内存中的内容,需要进行以下几步:
gcore产生 coredump 文件gdb加载 coredump 文件(gdb) dump binary memory result.bin {start_addr} {end_addr}命令 dump 内存- 使用 Vim 打开二进制文件,使用
:%!xxd的方式查看内容
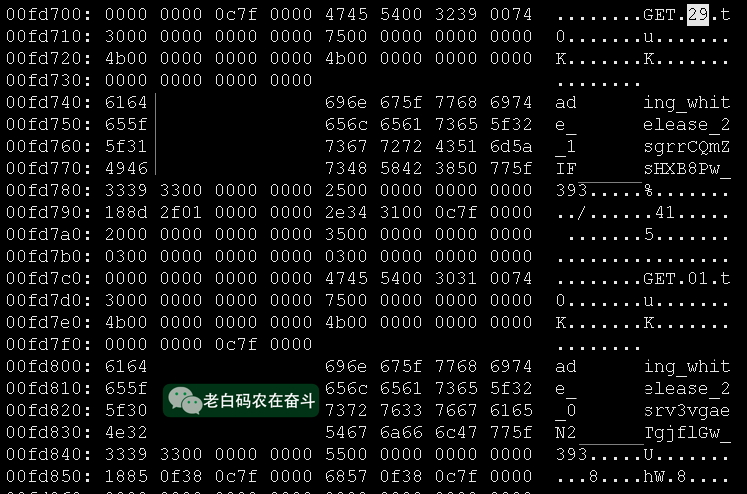
将内存中可读的、有意义的字段发给开发同学,开发同学看出这是一个 Redis 的 Key。而整段的内存,也是 Redis 操作相关的一个结构体,包括其中的 GET 是 Redis 指令。
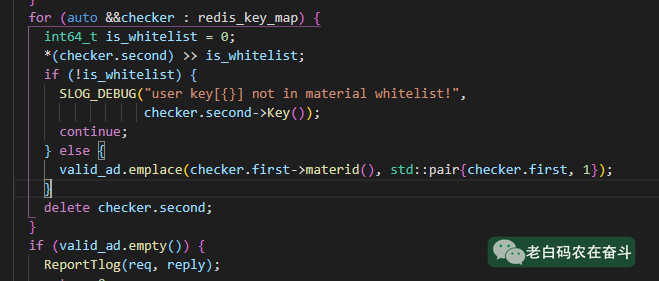
5. 定位内存泄露的代码
通过 GET 和 Key 的结构,开发同学很快的定位到了内存泄露的位置,for 循环的第一个分支中 continue 造成了部分内存没有清除。
开发同学表示,自己的测试用例没有覆盖到这里,所以自己多次使用 Valgrind 进行排查也没有发现。
修改之后上线,内存不在增长,如本节第一张图最后一段展示的那样。
四、多线程虚拟内存不足
1. 背景
运维对集群的扩容,增加 Router 并将新增 Router 列表配置下发到 Worker 供 Worker 向新增 Router 进行注册,下发之后 Worker 不断重启。
Worker Server 文件为 32位 ELF 文件:
# file worker_svr
worker_svr: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.18, not stripped
2. 问题排查
Worker 是因为 Crash 而重启的,Crash 的时候有产生 core 文件,直接查看 Crash 的原因:
Core was generated by `/data/xxx/bin/worker_svr ...'.
Program terminated with signal 11, Segmentation fault.
#0 0xf77a4086 in pthread_detach () from /lib/libpthread.so.0
(gdb) bt
#0 0xf77a4086 in pthread_detach () from /lib/libpthread.so.0
#1 0x080a8cf7 in base::Thread::detach (this=0xa11f1a8, thread=0) at base_thread.cpp:481
#2 0x080a86d4 in base::Thread::run (this=0xa11f1a8, ret=0x0) at base_thread.cpp:195
#3 0x08059774 in Monitor::start (this=0xa0b0500) at monitor.cpp:35
#4 0x08057109 in main (argc=11, argv=0xffcaf8f4) at main.cpp:408
(gdb) p errno
$1 = 11
可以较为明显地看到:
-
进程因为 “signal 11, Segmentation fault” 而崩溃
-
在调用
pthread_detach ()时发生了错误,errno为 11-EAGAIN
根据上边两个错误,以及 pthread_create() 说明文档 可以比较容易确认是内存不够而导致的创建线程失败。
通过另外一个方面也可以印证,coredump 文件大概有 4 GB 左右:
# ls -lh /data/corefile/core_worker_svr_1635134468.39137
-rw------- 1 user00 users 3.9G 10月 25 12:01 /data/corefile/core_worker_svr_1635134468.39137
3. 虚拟内存耗尽原因
32-bit 的进程虚拟内存为 4 GB,其中包含内核虚拟存储 1 GB,用户可以使用的有 3 GB 存储空间。
通过 Crash 产生的 coredump 文件,无法直接使用 info proc mappings 的方式来查看内存分布情况,因为这个命令是需要查看 /proc/{pid} 中的内容获得的。虽然有其他一些途径可以查看 Crash 的进程的内存分布,但为了方便,我还是直接 gcore 线上一个正常运行的进程来看看:为什么增加 Router 会导致内存耗尽。
(gdb) info proc mappings
Start Addr End Addr Size Offset objfile
0x8048000 0x827a000 0x232000 0 /data/xxx/bin/worker_svr
0x827a000 0x827c000 0x2000 0x232000 /data/xxx/bin/worker_svr
0x827c000 0x827d000 0x1000 0
0x8d49000 0x9988000 0xc3f000 0 [heap]
0x29d00000 0x29d21000 0x21000 0
0x29d21000 0x29e00000 0xdf000 0
0x29f00000 0x29f21000 0x21000 0
0x29f21000 0x2a000000 0xdf000 0
0x2a4fe000 0x2a4ff000 0x1000 0
0x2a4ff000 0x2c4ff000 0x2000000 0 [stack:51349] <----- 32MB
0x2c4ff000 0x2c500000 0x1000 0
0x2c500000 0x2e500000 0x2000000 0 [stack:51346] <----- 32MB
可以发现,内存中有比较大的块 32MB 出现了 91 次,这部分内存加起来总共占用 2912MB。通过 info threads 命令查看,是有 96 个线程。两者有高度的关联性。
选一个线程进行具体的观察:
(gdb) t 88
[Switching to thread 88 (Thread 0x3aaa6b70 (LWP 6410))]#0 0xf7746440 in __kernel_vsyscall ()
(gdb) bt
#0 0xf7746440 in __kernel_vsyscall ()
#1 0xf750b4a6 in epoll_wait () from /lib/libc.so.6
#2 0x080a7b78 in base::TCP_Client_Epoll::svc (this=0xba25b50) at base_tcp_client_epoll.cpp:188
#3 0x080a817a in base::thread_proc (arg=0xba25b50) at base_thread.cpp:34
#4 0xf771ab39 in start_thread () from /lib/libpthread.so.0
#5 0xf750ac2e in clone () from /lib/libc.so.6
打印线程的两个栈相关的寄存器:栈指针寄存器(extended stack pointer, 指向系统栈最上面一个栈帧的栈顶) 和基址指针寄存器(extended base pointer, 指向系统栈最上面一个栈帧的底部):
(gdb) info register esp ebp
esp 0x3aaa6070 0x3aaa6070
ebp 0x3aaa60e8 0x3aaa60e8
这两个地址均落在上边的 mappings 的一块 32MB 的区域中:
Start Addr End Addr Size Offset objfile
0x38d00000 0x3ad00000 0x2000000 0 [stack:55003]
所以可以确定每个(大部分)线程创建时,会申请这样一部分空间,而这部分其实就是线程的栈空间,参考《深入理解计算机系统》 12.3 基于线程的并发编程。
至于每个线程创建时会分配多大的栈空间,在 pthread_create() 的手册中有说明:
- 使用
pthread_attr_setstacksize()显式地设置 - 使用
ulimit -s设置 - 如果
ulimit -s设置成unlimited,将使用架构默认值,比如 i386 和 x86_64 默认都是 2MB
我们的进程没有设置,而 ulimit -s 的值是 32768 kb,恰好为 32 MB,与看到的上述现象相符。
简而言之,这种现象是因为配置中每增加一个 Router 就会对应创建一个线程进行注册和连接管理,当 Router 太多就会引起线程过多而造成虚拟内存耗尽。
这里引出了几个问题:
- 为什么线程间切换有损耗?
- 一个进程可以启用多少个线程?
- pthread - Posix 线程 有哪些常用接口?
4. 改进方法
- 经过评估,我们进程中所使用的线程的栈会远小于 32MB,因此直接在进程中通过
pthread_attr_setstacksize()设置为 2MB - 可以重新编译为 64-bit 版本
五、相关知识
1. Linux上进程内存布局
32-bit 和 64-bit 虚拟内存地址的分布如下(图片来源):
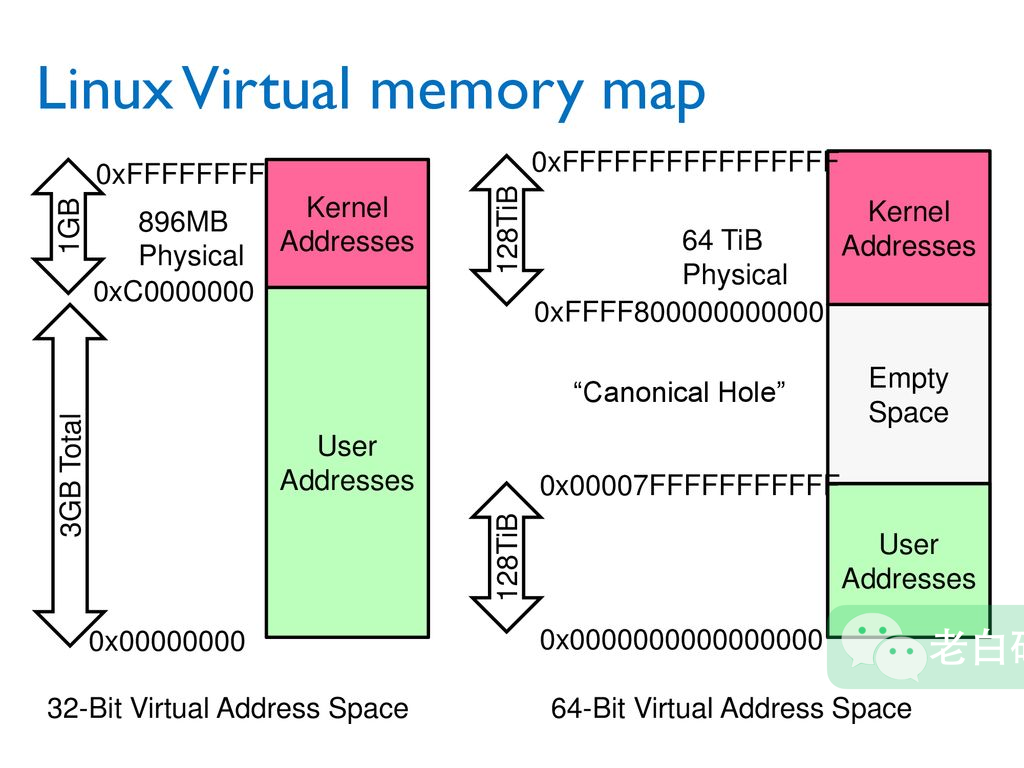
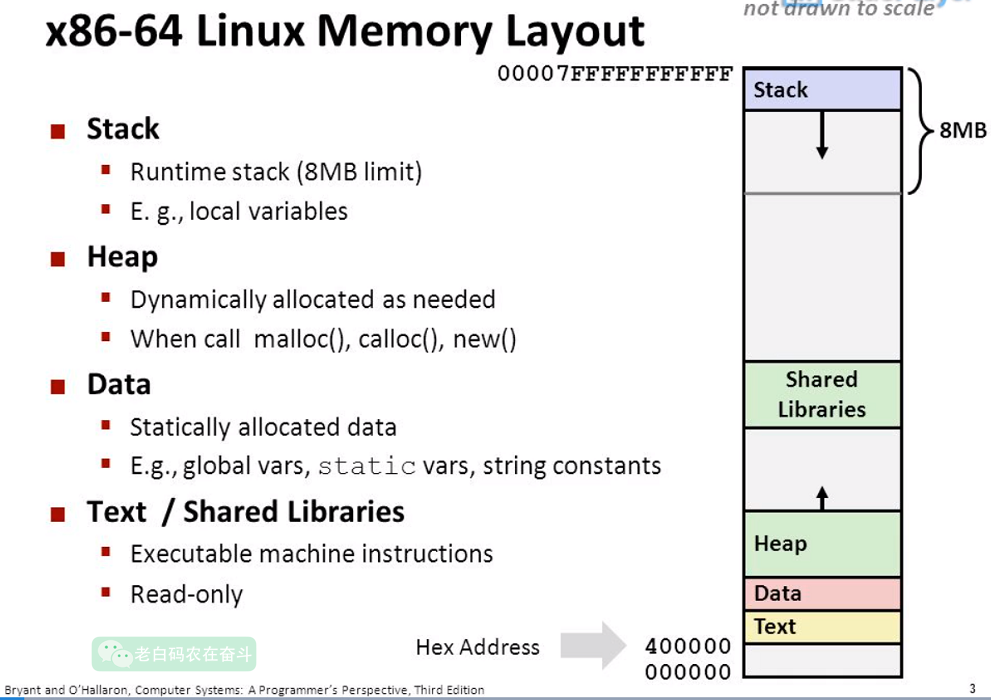
右侧 64-bit 的用户地址(绿色部分)又会做以下划分为(图片来源):
2. 常用命令选项介绍
top -b -n 1 -H -p 12877
-b 表示 Batch-mode,能避免输出中有 ANSI escape codes,进而造成后续 grep 不符合预期的情况。
-n 1 只打印 1 帧,-H 显示多线程。
diff pmap.01.log pmap.02.log | #
awk '{if($4 > 0){print $0}}' | #
sort -k2 -k1
sort -k2 -k1 先按照第二列排列,第二列值相同的,按照第一列排列。
3. 常见问题
Q: 使用 pmap 找到了内存增长的地址,但是在 GDB 中info proc mappings 没有看到对应的内存地址,可以直接 dump 内存吗?
A: 可以。