日志工具优化 - 从14秒到0.4秒
潘忠显 / 2022-08-25
本文介绍一个简单日志查询工具的优化过程,包括原有工具的耗时分析、优化方法和效果,以及通用化工具的思考。
花小半天时间,用二分查找优化了一下,从原来耗时 14 秒降到了 0.4 秒。
背景
某个 RPC 服务,处理逻辑、上下游交互的具体日志,会落在服务器的硬盘上。每次 RPC 有唯一的 msg_id,该 msg_id 中有发生的时间戳以及 Router IP。
外包同学在协助排查问题时,需要查询详细日志,只能联系正职根据 msg_id 到机器上进行 grep。虽然通过 msg_id 已经能较精确的找到 Router 上的文件,但服务架构上有多层,还需要再进一步的查询 Worker 上的日志,费时费力。
DRY - Don’t Repeat Yourself.
于是我就写了一个日志查询到服务,在 Router 和 Worker 上都部署一个服务,在管理端的机器上可以通过 RPC 让 Proxy 和 Worker 上的服务进程,模拟找到日志文件而后 grep 的动作。这样一来,外包同学在页面上输入 msg_id 即可获得需要的日志。

上边的方案查一次日志需要15秒左右,有改善的空间。接下来针对这个长耗时做分析和优化。
耗时分析
15 秒的耗时,包括先查询 Router 日志,并得到 worker_id,然后再去查询 Worker 日志。也就是看单独的 Router 或者 Worker 日志查询大概在 7 秒左右。
Router 和 Worker 日志文件都是按照大小进行切换的,每一个大概在 1.1G 左右。
大部分要查询的日志,都已经从内存 Cache 中被移除。如果需要再次查询,则需要将文件从硬盘上加载到内存当中。下边这个图就是 CSAPP 中对不同层次存储的一个描述:
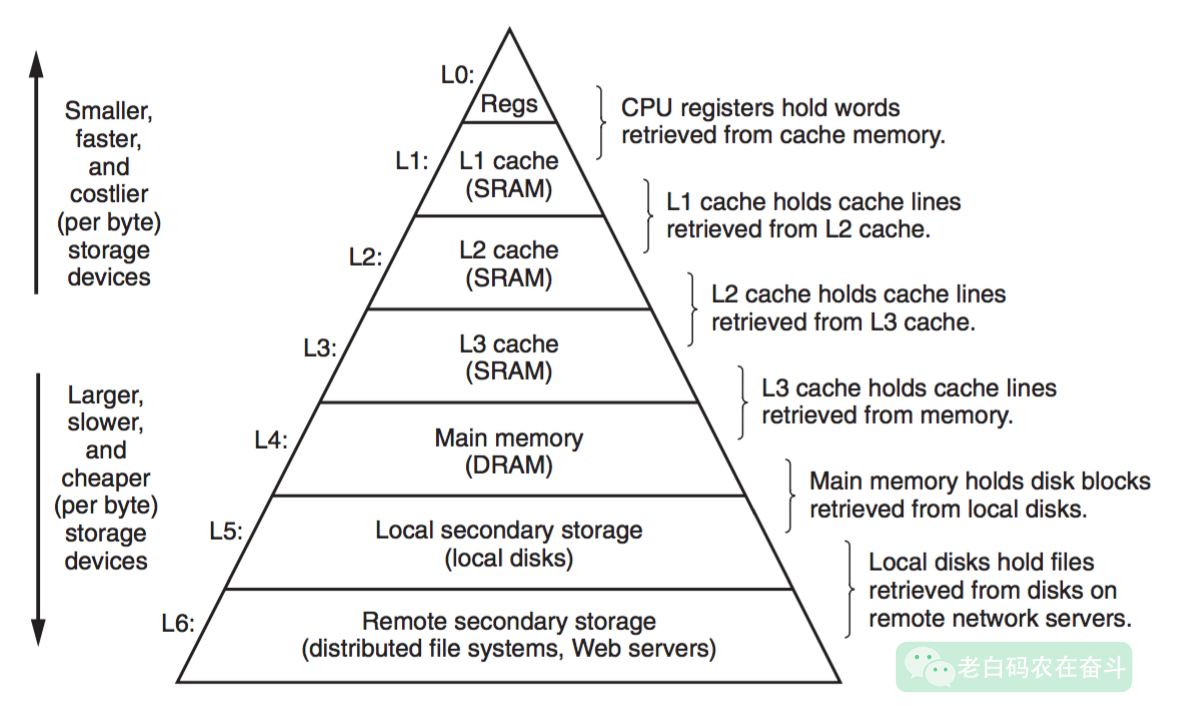
机械硬盘典型的读速度在 100MB 到 200 MB 之间,所以仅仅是将这 1.1G 的文件加载到内存就需要5秒以上。我们可以通过几种方式,实际测试一下这部分耗时。
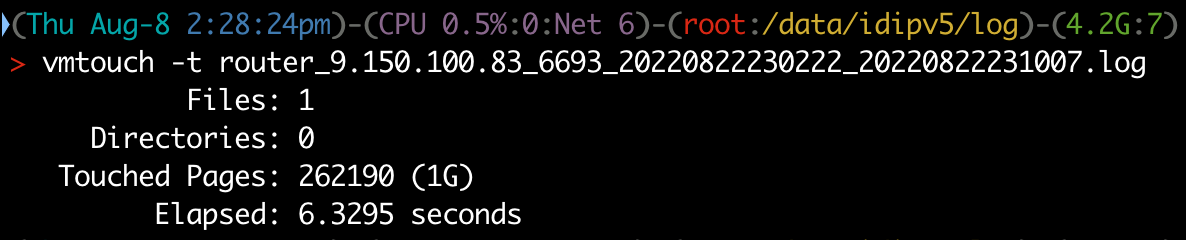
vmtouch
vmtouch 是一个管理和查询文件系统Cache的工具。-e 是将某个文件从 Cache 中移除,-t 是将文件加载到 Cache 中,-v 是看文件有多少内容在 Cache 中。
为了防止文件已经被加载到 Cache 中,我们每次测试之前,都会调用 vmtouch -e 做一下清理。

我们将文件加载到 Cache 中,大概用了 6.3 秒:
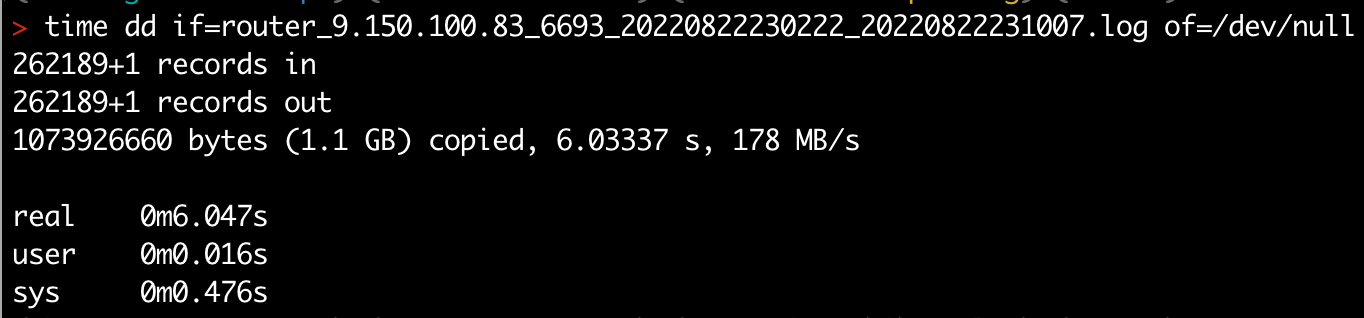
dd
dd 命令可以拷贝一个文件,同时还能打印拷贝的速度。这里将文件拷贝到特殊的 /dev/null,就能测量出读文件的速率 178MB/s,总耗时大概在 6 秒。
grep
这里也用 grep 去做一下测试,模仿一下手工搜索日志的过程。这个过程中包括两部分,一部分是加载到内存的时间,另外一部分是进行相关过滤动作,产生的CPU耗时。

优化方向
上边三种工具耗时比较,能得结论:
- 从磁盘加载到内存的时间,是耗时的主要部分
- 搜索文件内容的计算部分,耗时占相对较低
一条 msg_id 产生的日志,会落在时间戳前后10秒内。因此,如果能快速地找到 msg_id 前后的文件内容进行加载,而不是加载整个文件,将能够明显缩短耗时。同时,这还将大大减少第二部分搜索过滤带来的 CPU 消耗。
日志文件有一个重要特点:每行的时间是递增的,这样我们就能使用二分查找,迅速地找到指定时间范围的文件偏移量。
string GetIntervalContent(const char* filename, int start_ts, int end_ts) {
off_t left = LowerBound(filename, start_ts);
off_t right = LowerBound(filename, end_ts);
string ret;
ret.resize(right - left);
int fd = open(filename, O_RDONLY | O_NOATIME);
lseek(fd, left, SEEK_SET);
off_t n = read(fd, const_cast<void*>(static_cast<const void*>(ret.data())),
right - left);
ret.resize(n);
close(fd);
return ret;
}
其他优化:
- 读出小范围文本后,使用
string_view处理,没有额外的拷贝 - 使用 Abseil 库 StrSplit 进行切分,使用 <regex>,精简代码
优化效果
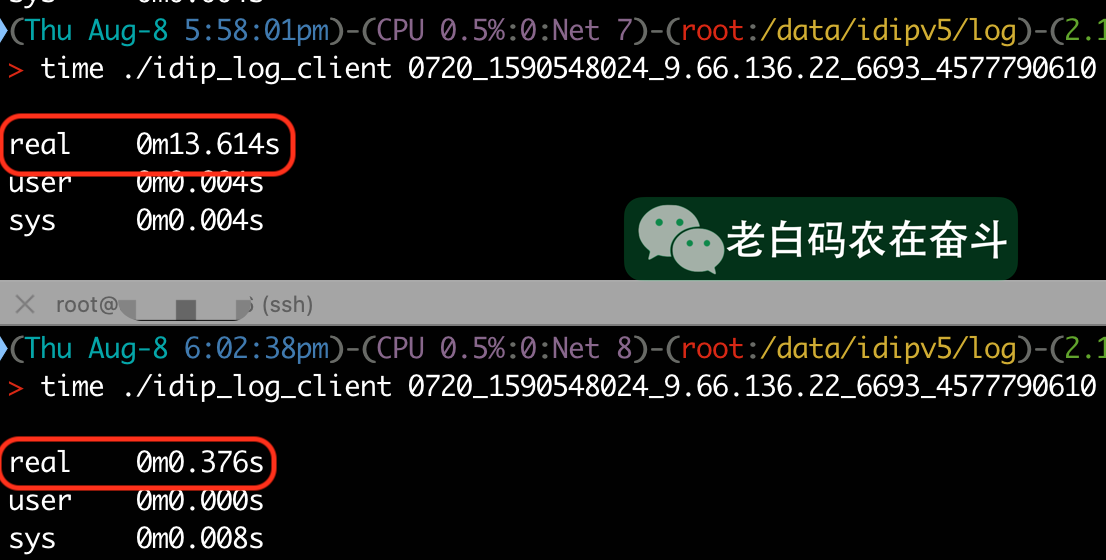
接下来展示的三个图,每张图中上半部分使用的老服务,下半部分使用的新服务,用于进行对比。
时间比较
耗时从 13.6 秒降低到 0.38 秒:
内存比较
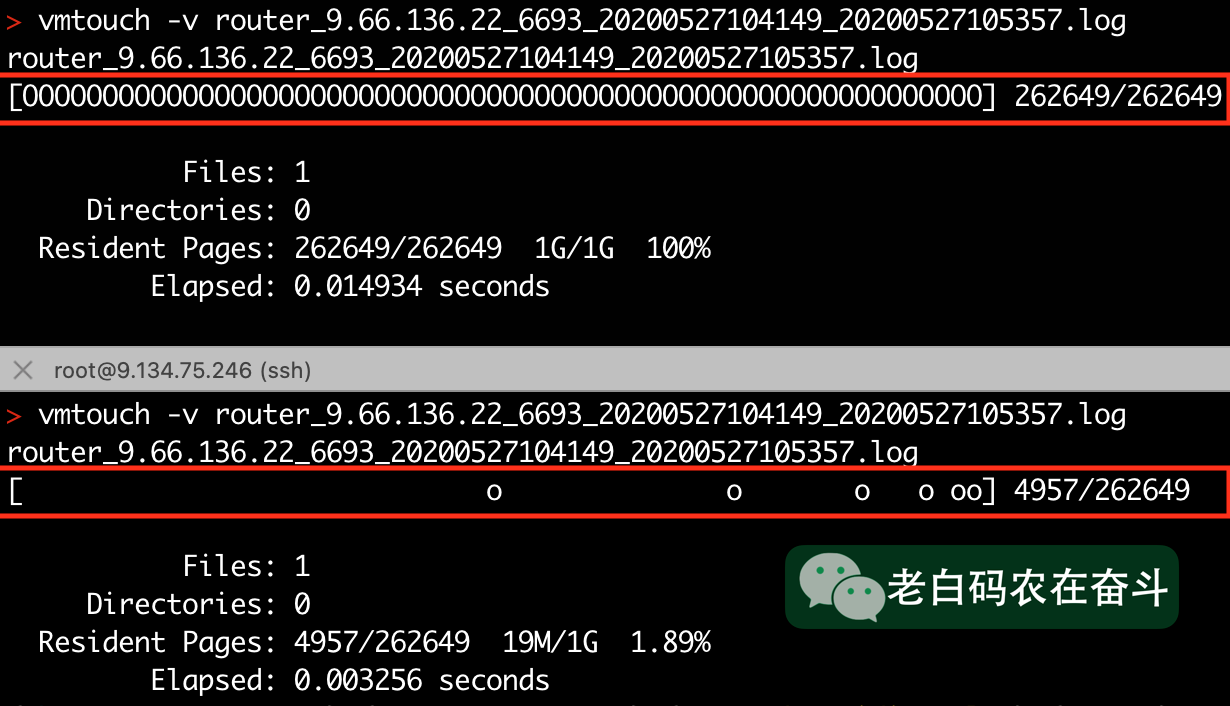
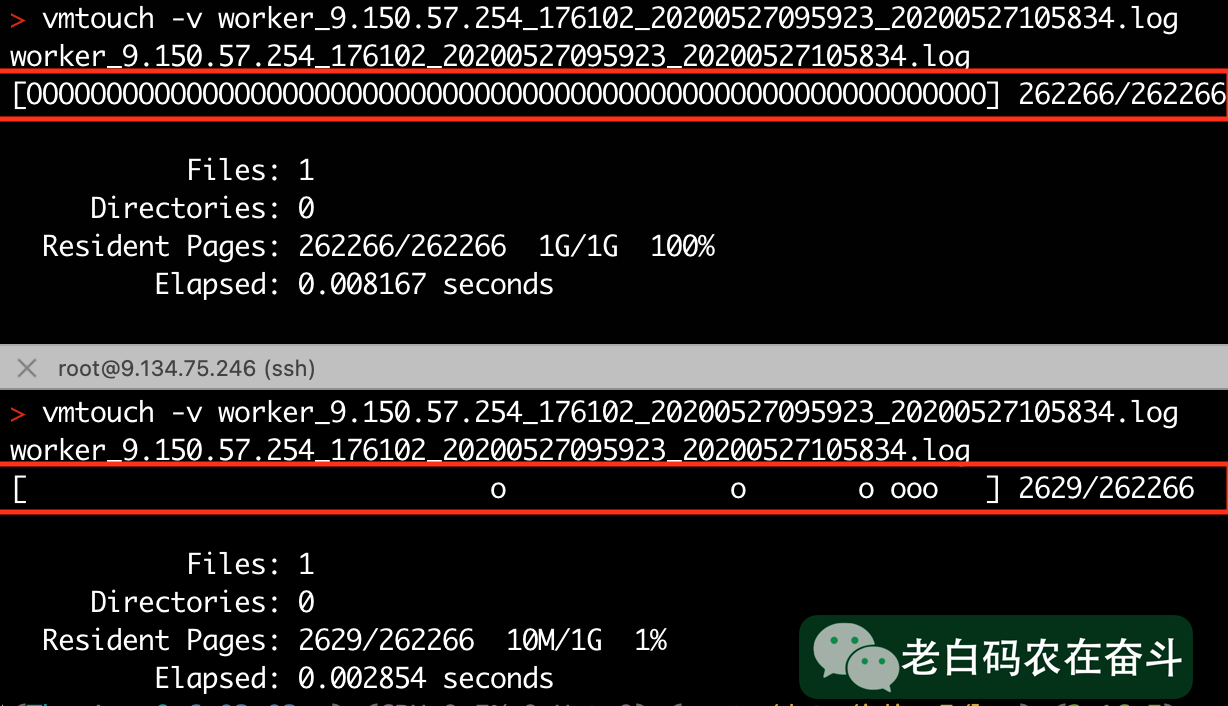
文件内容被 Cache 的部分,能够明显的展示出二分查找的痕迹。优化前需要Cache 整个文件,而优化后只需要 Cache 1% 的内容
Router 日志加载到 Cache 的情况:
Worker 日志加载到 Cache 的情况:
额外思考
目前,好像没有现成合适的工具来做这种时间序列日志的过滤,而这种日志非常的普遍,比如:/var/log/messages,Apache 日志等,有些因为配置不合理造成单个文件上G很常见。
可以开发一个工具,指定日志中的时间字段,然后做快速的范围缩小,然后获得对应日志。用法可以参照 awk 等命令:
tgrep -F '|' -t 2 `# 使用|切分的第二个字段` \
--format="%Y%m%d%H%M%S" `# 日志中时间格式` \
--start="20220825100000" `# 符合时间格式的起始时间` \
--end="20220825100100" `# 符合时间格式的结束时间`