构建大数据处理流水线
潘忠显 / 2023-04-02
[TOC]
大数据已经势不可挡,每个企业都可以利用数据。当前各种组织面临的一个重要挑战是:设计能够将数据快速转化为战略决策的强大系统。
要应对这一挑战,就需要建立大数据处理流水线。它有非常多的应用场景,例如:
- 对用户输入(例如点击或键盘事件)做出反应的社交媒体分析系统
- 从传感器读取指标并将输入给执行器的 IoT 应用程序
- 检查潜在欺诈行为的银行交易审计系统
本文会依次介绍大数据相关组件选择,Kafka、Flink 和 Cassandra 的设置和启动,建立 Scala 数据处理项目,Flink 提交并运行任务。通过一个实际项目,构建出大数据处理流水线。
通过实际操作,你会熟悉各种大数据组件的使用,完成大数据处理的 Hello World!
一、组件的选择
如果你在大公司或者是使用云上的集群服务,Kafka、Flink 集群会作为基础设施,是可以直接使用的。即使在本机,这些组件也是可以通过 Docker 直接使用。但是为了更清楚地理解这些组件、语言之间的关系,下文会使用从官网下载压缩包、通过提供的脚本配置和启动 Kafka和Flink。
通常大数据的处理,会使用消息队列接收下海量数据,然后用流计算平台去消费数据并计算,最后会汇总在不同的存储中。当然,也会有多级连接的情况,比如中间计算结果会再进入到消息队列,再次经过流计算系统等等。
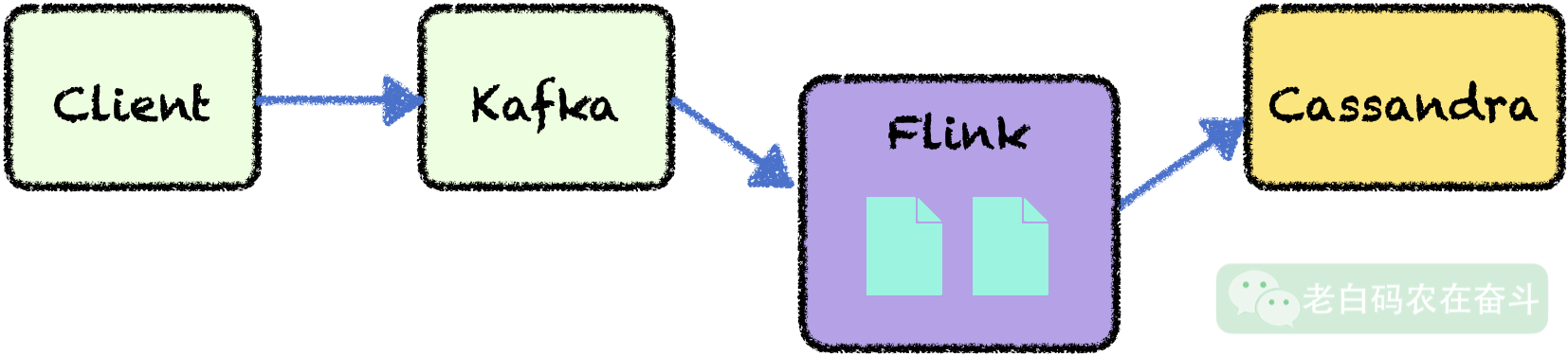
Apache Flink
Apache Spark 是一个被大规模使用的开源框架,允许近乎实时的数据处理。 Apache Spark 不提供原生流处理。Spark使用微批处理,可以模拟实时。相比于 Spark, Apache Flink 更专注于实时处理,延迟要低于 Spark,而且其作业优化是自动完成的,使用者无需关注 shuffles, broadcasts 等操作。
Apache Kafka
消息队列有不少组件可供选择。他们的侧重点会略有不同,一些侧重易于集成,另一些可能侧重健壮性等。
最受欢迎的消息代理之一是 RabbitMQ,它可以在许多用例中充当消息流的可靠来源。但当涉及到大数据应用时,有些属性 RabbitMQ 就很难保证了。比如分区容错性、高吞吐量、水平可伸缩性和强冗余。
而在这些方面,Kafka 都有一些优势,使其成为大数据实时处理的常用消息队列选择。
Scala 语言
Scala 是一种发展非常迅速的语言,它同时具备面向对象编程范式的优点,以及函数式编程语言的优点。它具有令人很强的通用性、简洁性,以及相当高的性能。Scala 可以被编译成 Java 字节码,最终由 JVM 执行。
Spark 使 Scala 成为大数据应用程序的顶级编程语言之一,Spark 使用 Scala 会获得很好的性能。这使得大数据生态系统将 Scala 视为一种优雅且高效的语言。另外,Flink 和 Kafka 都是用 Scala(以及 Java)编写的。
Apache Cassandra
Cassandra 是一个 NoSQL 分布式数据库。目前DB-Engines上排名11,这里演示选择 Cassandra 有几个原因:Apache 项目,Flink有官方连接器;配置和接口都比较简单;可顺便了解一下这个数据库。
组件版本
- Java 1.8 因为 Scala 依赖,使用OpenJDK 的其他版本可能有问题
- Scala 3.2.2 编译器可以兼容老的版本
- Flink 1.15.4 - 2023-03-15,因为公司内流计算平台使用的这个版本 1.15
- Kafka 3.4.0 (Scala - 2.13)
- Cassandra 3.11.14
二、环境搭建
我这里使用的MacBook进行实验。
2.1 基本环境
安装 Java 1.8,使用OpenJDK可能会遇到一些奇怪的问题。
brew install openjdk@8
export PATH="/usr/local/opt/openjdk@8/bin:$PATH" # 可以添加到 ~/.zshrc 中
安装 Scala,根据Scala 官方指引,在 MacBook 上可以直接使用 brew 安装:
brew install coursier/formulas/coursier && cs setup
在安装完之后,会有以下命令行工具可用:
scalac:Scala 编译器scala:Scala 的REPL(交互解释器)、运行器,类似于java和python命令的作用scala-cli:Scala CLI, Scala 交互套件sbt,sbtn:sbt 构建工具scalafmt: Scala 代码格式化工具,类似于gofmt
2.2 Kafka 配置
真正的解释清楚 Kafka 架构可能会很复杂,这里简化对 Kafka 的一些术语和原理做下解释。
Kafka 是一个事件流框架,这里提到的”事件“和消息队列中的”消息“两个词,具有相同的含义。事件 会被发送到指定的主题,主题 包含了一系列有序的事件。主题可以被分区(partitioned)和复制(replicated)。
Kafka 对外服务的节点,叫做代理(brokers),负责主题日志。Zookeeper 主要负责协调服务器和管理主题。所谓的Kafka 集群,就是启动一个由 Zookeeper 协调的多个brokers。
通常,生产者将事件发送到指定 topic,消费者从这些主题消费。消费的时候,可以自己指定消费组,集群可以为不同的消费组记录消费到的位置,不会相互影响。
Kafka 的官方文档对其设计介绍的非常清晰,有兴趣的同学可以进一步阅读:https://kafka.apache.org/documentation/#design。也有一个相对简单的介绍,可以了解:https://www.instaclustr.com/blog/apache-kafka-architecture/
启动本地 Kafka 集群
使用 Kafka binary 包,需要从Kafka 官网上下载压缩包,进行解压(上图中 Scala 2.13 对应的版本),有两个文件夹可以关注一下:
- bin/ 工具shell脚本,用于运行 Zookeeper 和 Kafka Broker,以及管理、查询主题等功能
- config/ 配置文件(.properties类型),用于运行 Zookeeper 和 Broker 的配置
启动 Zookeeper:
./bin/zookeeper-server-start.sh ./config/zookeeper.properties
启动一个 Broker:
./bin/kafka-server-start.sh ./config/server.properties
创建一个主题(主题叫 flink-input,只复制一次,指定 server 地址):
./bin/kafka-topics.sh --create --topic flink-input --replication-factor 1 --bootstrap-server localhost:9092
上边复制因子(replication-factor)设置的只能是1,因为我们只启动了一个代理的,而复制因子不能超过代理数量。
生产和消费消息
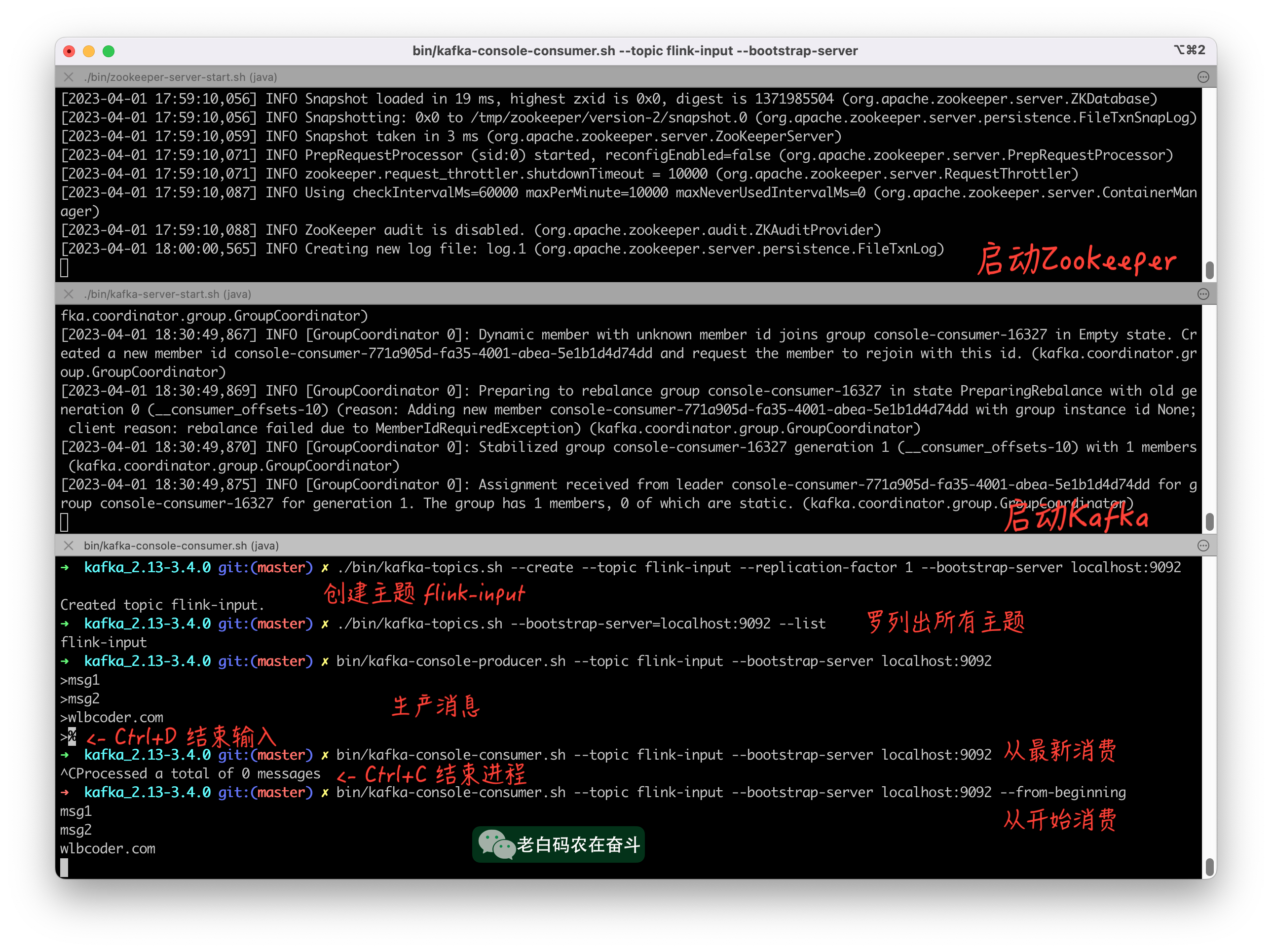
这里先直接使用Kafka 提供的脚本工具,测试一下消费的生产和消费。
查询当前 Kafka 中有哪些主题(目前只有 “flink-input”):
./bin/kafka-topics.sh --bootstrap-server=localhost:9092 --list
生产消息(将消息塞入到指定主题),首先运行下边命令,会出现一个交互模式,在交互模式下,每一行会作为一个条消息存储在 Kafka 的主题中:
bin/kafka-console-producer.sh --topic flink-input --bootstrap-server localhost:9092
消费消息,这里跟 producer.sh 的参数区别在于加了个 --from-beginning 表示从头消费;如果不加,默认是从尾部开始消费:
bin/kafka-console-consumer.sh --topic flink-input --bootstrap-server localhost:9092 --from-beginning
2.3 Flink 配置
与上节对 Kafka 的术语和框架介绍类似,这里简单地描述一下 Flink 的作业管理器和任务管理器。
- 作业管理器:负责协调应用程序执行的进程,尤其是分布式应用。包括调度作业、调解资源访问、关键事件处理(例如节点故障)等
- 任务管理器:负责对数据的实际操作。它们有插槽 slot,实际处理线程。
Flink 的官方文档对架构的介绍,也是非常清楚的,图文并茂,可以进一步去了解。
启动本地 Flink 集群
需要注意的是,Flink 1.15.4 是基于 Scala 2.12 的。所以后边开发应用程序,应该在 SBT 中做配置,不然当安装了不同 Scala 版本时会有问题。
从 Flink 官网下载对应的包,我这里选的 “flink-1.15.4-bin-scala_2.12.tgz",不仅下载解压和上节 Kafka 的处理非常相似,其目录结构和启动方式也非常相似:
- bin/ 启动 flink 集群的脚本目录
- conf/ 配置文件目录
- log/ 中存储者执行作业时写入的日志,以及集群运行信息
启动 Flink 集群:
./bin/start-cluster.sh
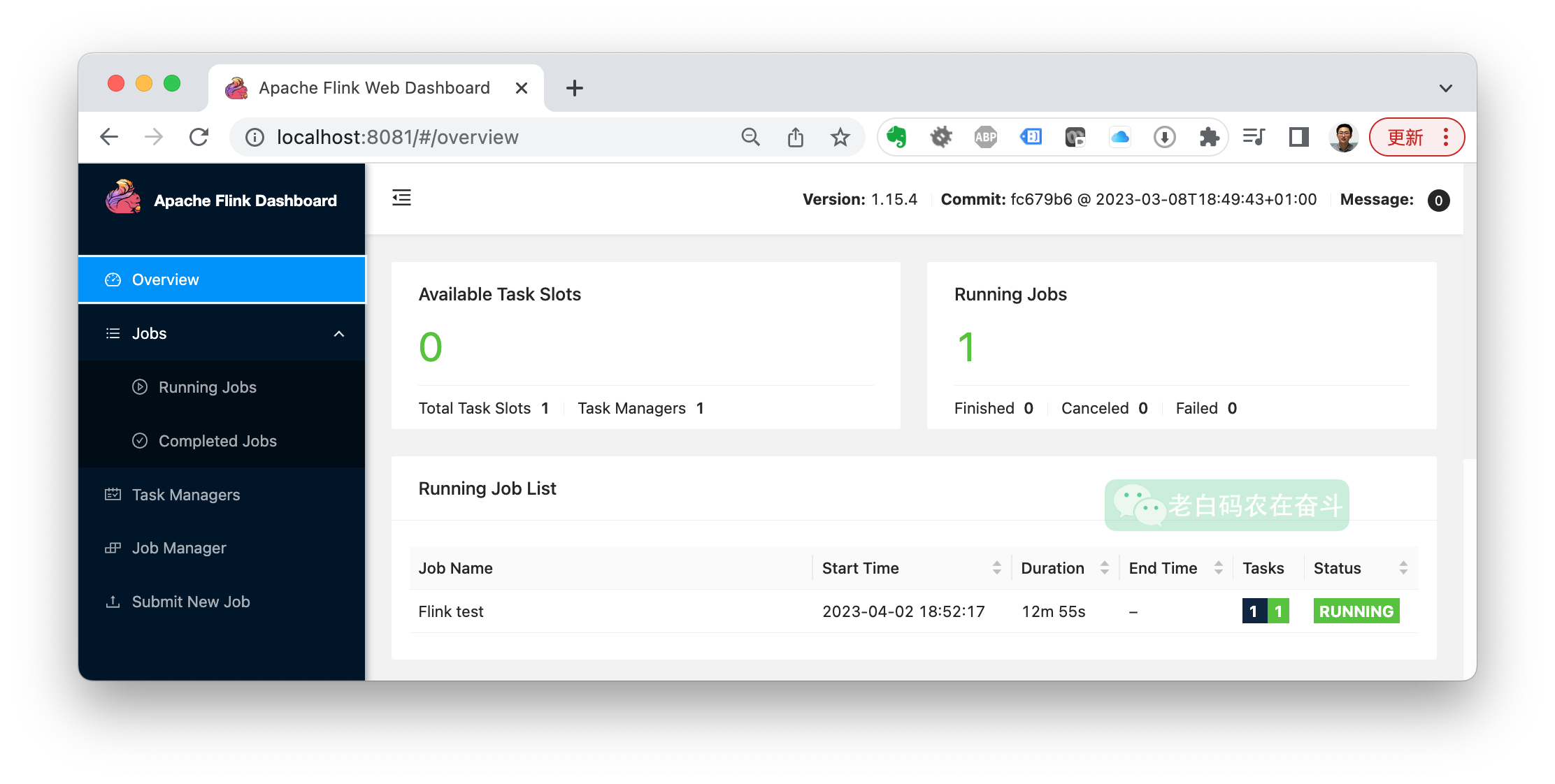
启动集群之后,Flink 准备好了接收要运行的作业。可以浏览器访问http://localhost:8081,直接通过其 Web UI 检查运行状态(可以看到有1个可用的 Slot):
提交 Flink 任务
Flink 允许我们提交 .jar 文件。接下来一节,会创建一个简单的 Scala 应用程序,生成 .jar 作为 Flink 的作业,再进行提交任务的演示。
查看 Flink 日志
调试 Flink 应用程序可能很棘手,但是可以通过查询 Flink TaskExecutor 作业输出日志,快速了解具体发生了什么。需要切换到 Flink 根目录下运行:
tail ./log/flink-*-taskexecutor-*.out
2.4 配置 Cassandra
这里直接拉取容器,来启动一个 Cassandra 服务(服务会使用到9042端口):
docker run -p 9042:9042 –rm –name cassandra -d cassandra:3.11
利用镜像中的 cqlsh 跟 Cassandra 服务进行交互。CQL 代表 Cassandra 查询语言(Cassandra 不是SQL):
docker exec -it cassandra cqlsh
创建键空间和包含单列的表,进入交互模式后,输入CQL语句:
CREATE KEYSPACE cassandraSink WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1'};
USE cassandraSink
CREATE TABLE IF NOT EXISTS messages (payload text PRIMARY KEY);
等我们的 Flink 启动以后,就可以进入到 cqlsh 来查询键空间中是否有对应的消息了:
SELECT * FROM cassandraSink.messages;
三、Scala 应用程序
前文其实有提到 Scala 可以按照官网的步骤进行安装,安装完之后,会有 sbt 指令可以用。sbt 是 Scala 社区中首选的包管理器, sbt 还提供了一些用于开始使用 Scala 的模板项目。
创建一个Scala 2项目,非常简单(会提示输入项目名,我这里命名为 “hello-world”):
sbt new scala/hello-world.g8
运行,跳转到项目目录下,可以直接运行:
cd hello-world
sbt run
经过编译和运行,很快就会看到打印的屏幕输出:
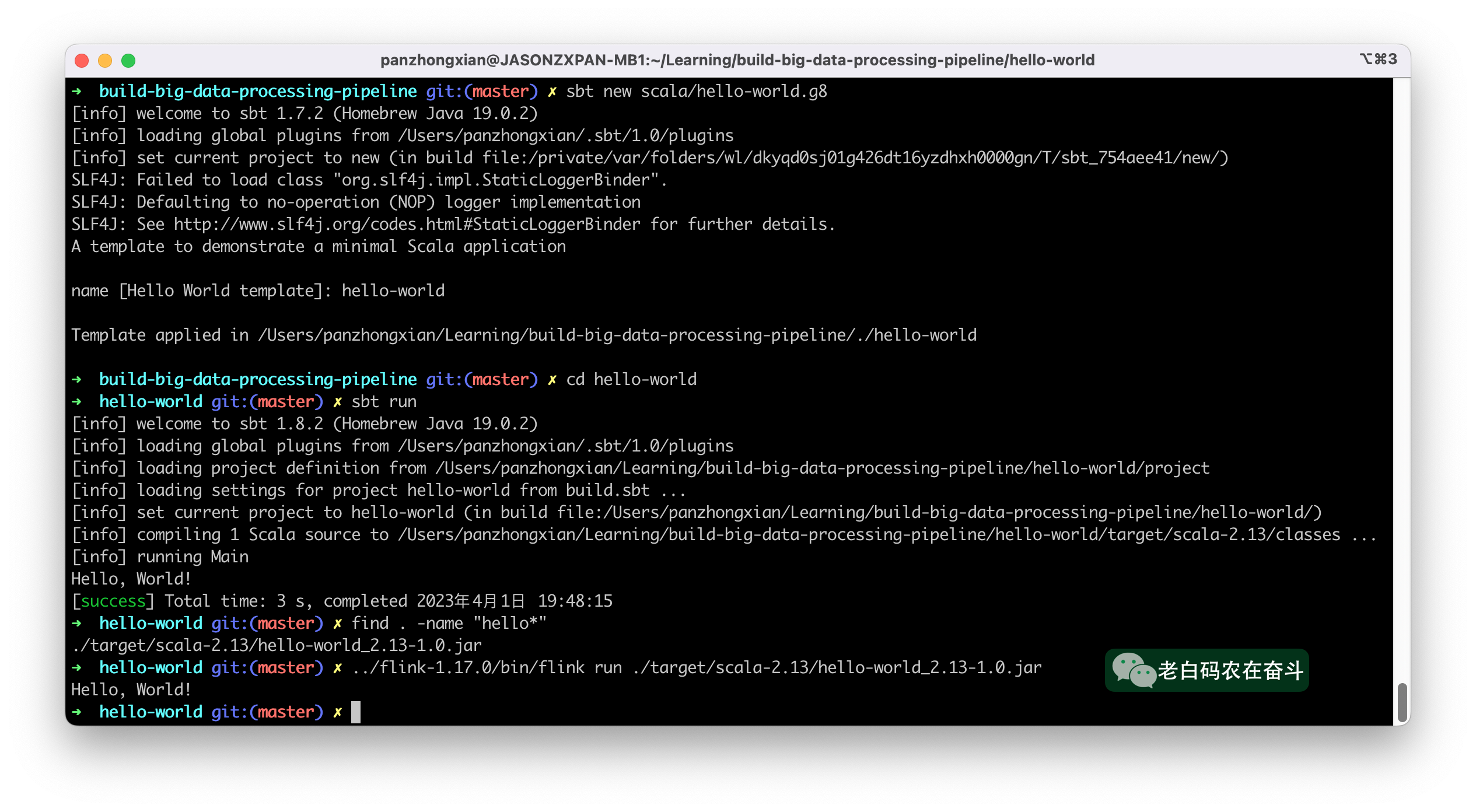
上边运行 sbt run 的同时,会产生对应 .jar 文件。上图中,最后还将其提交到 Flink 集群进行运行:
../flink-1.15.4/bin/flink run ./target/scala-2.13/hello-world_2.13-1.0.jar
3.1 SBT 配置
前面提到 Flink 允许我们提交自己的 .jar 文件,我们需要添加非 Flink 原生的依赖项,比如 connector。这些信息必须存在于 jar 中,一个包所有依赖的 jar 被称为 fat jar或uber jar。我们可以通过 sbt 管理这些包。
根据sbt 插件文档,在项目中安装插件的有效方法是创建一个"plugins.sbt"文件。此文件应位于项目根目录的 /project 目录中。
我们例子中,目前唯一插件是 assembly plugin。因此,我们的 plugins.sbt 应该是这样的:
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "1.2.0")
前边也介绍了,Flink 1.15.4 需要 Scala 2.12.7 才能运行,这里需要同时将 build.sbt 文件中的 scalaVersion := "2.13.x" 做替换:
scalaVersion := "2.12.7"
在build.sbt中,给 Scala 项目添加需要依赖的基础库:
libraryDependencies += "org.scala-lang.modules" %% "scala-parser-combinators" % "2.1.1";
libraryDependencies += "org.apache.flink" % "flink-core" % "1.15.0"
libraryDependencies += "org.apache.flink" %% "flink-streaming-scala" % "1.15.0";
libraryDependencies += "org.apache.flink" % "flink-connector-kafka" % "1.15.0";
libraryDependencies += "org.apache.flink" %% "flink-connector-cassandra" % "1.15.0";
libraryDependencies += "org.apache.flink" % "flink-clients" % "1.15.0";
build.sbt 文件中的每一条都是 设置表达式:表达式由一个键、一个运算符和一个值组成。最常见的设置表达式是依赖表达式,以上边最后一行为例:libraryDependencies 是一个键,+= 是个运算符,"org.apache.flink" % "flink-clients" % "1.15.0" 是值,% 分割的三个字符串分别代表 Maven 工件 group ID、artifact ID 和版本。
3.2 Scala 项目代码
本节会修改 hello-world 项目中的 ./src/main/scala/Main.scala 文件,将事件从 Kafka 中取出存储到 Cassandra 表的逻辑,用 Scala 代码实现。将数据从一个系统推送到另外一个系统的动作,有个术语来描述—— sink。
先看一下原来的代码文件,文件名和对象名需要相同(分别是Main.scala 和Main),对象扩展了 App trait:
- Main 是一个Scala 对象。对象类似于 Java 类,但它们只有一个实例。这是实现单例模式的 Scala 原生机制
- Scala trait 类似于 Java interface,在 Scala 2 中,扩展 App trait 与在 Java 中实现 main 方法是一样的
object Main extends App {
println("Hello, World!")
}
接下来,替换 Main.scala 的内容:
import org.apache.flink.api.common.eventtime.WatermarkStrategy
import org.apache.flink.api.common.functions.FlatMapFunction
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.cassandra.CassandraSink
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
import org.apache.flink.util.Collector
import org.apache.flink.streaming.api.scala._
object Main extends App{
// 环境初始化。配置 CheckpointingMode
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.enableCheckpointing(60000, CheckpointingMode.EXACTLY_ONCE)
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
// 构造 KafkaSource,用于从中消费消息
val source : KafkaSource[String] = KafkaSource.builder()
.setBootstrapServers("localhost:9092")
.setTopics("flink-input")
.setGroupId("group1")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build()
// 定义如何处理source种获得的消息。在Scala中,CassandraSink 只能使用Tuples
val tuples = env.fromSource(source, WatermarkStrategy.noWatermarks(), "KafkaSource")
.flatMap(
new FlatMapFunction[String,Tuple1[String]]{
override def flatMap(t: String, collector: Collector[Tuple1[String]]): Unit =
collector.collect(Tuple1[String](t))
}
)
// 将处理后的消息下沉到 Cassandra
CassandraSink.addSink(tuples)
.setHost("127.0.0.1")
.setQuery("INSERT INTO cassandraKafkaSink.messages (payload) values (?);")
.build()
.name("flinkTestSink")
//executing Flink job
env.execute("Flink test")
}
3.3 项目打包
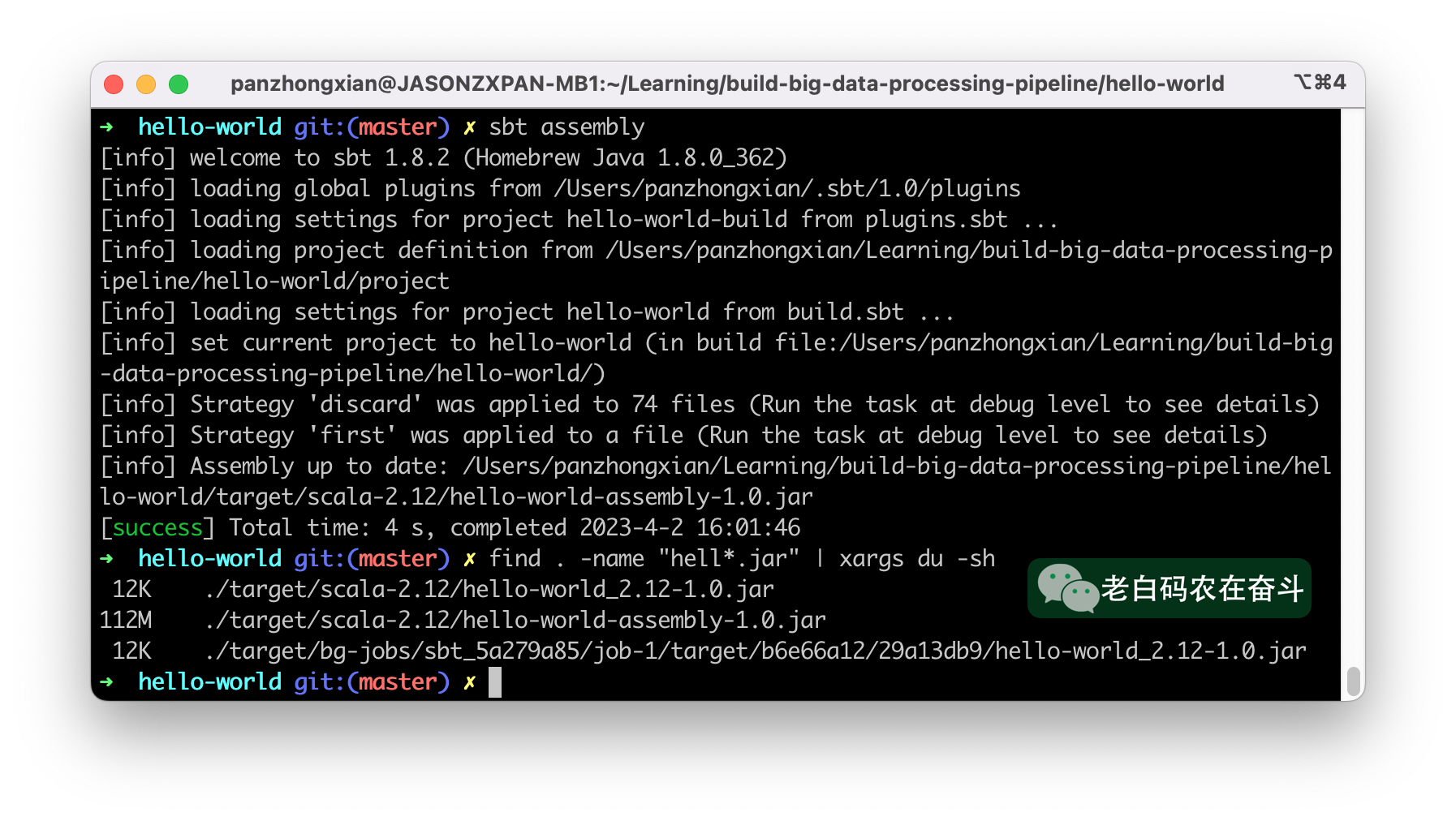
前面也曾提到过,我们要提交的 jar 文件需要将所有的依赖都打进去,因此我们需要执行指令:
sbt assembly
这样之后会得到一个完整的包,路径类似于“./target/scala-2.12/hello-world-assembly-1.0.jar”,可以看到单独的 jar 文件是12K,完整的包则是 112M。
四、提交 Flink 任务
经过前面几节的介绍,当前我们的服务器上,已经有了以下的服务和文件:
- Kafka 服务
- Flink 集群服务
- Cassandra 服务
- hello-world-assembly-1.0.jar 包
万事俱备,本节就来提交一下 Flink 作业,然后进行测试。
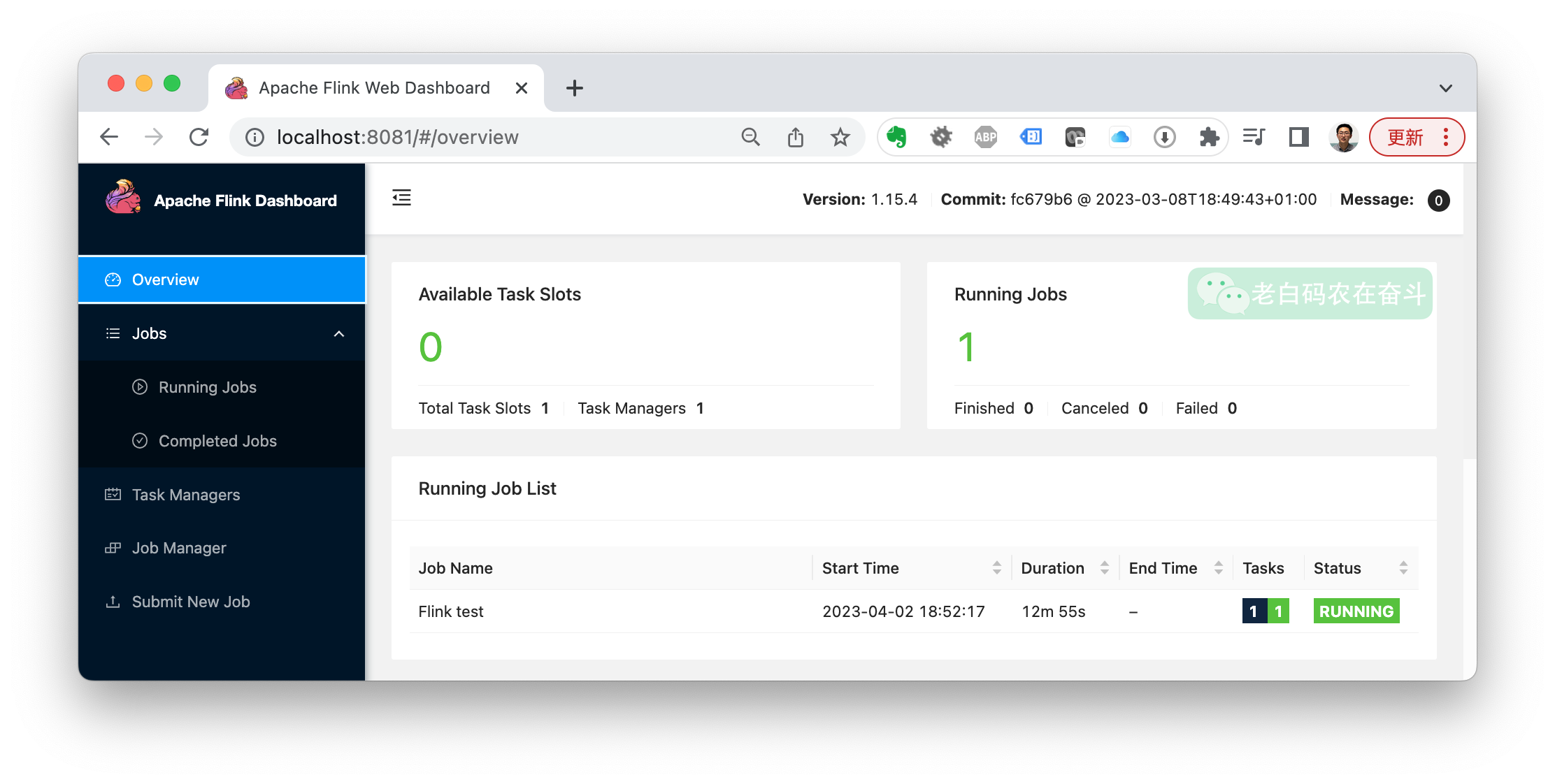
提交任务可以从前面提到的 http://localhost:8081/#/submit Web UI 进行操作,也可以直接命令行操作:
../flink-1.15.4/bin/flink run ./target/scala-2.12/hello-world-assembly-1.0.jar
然后在管理端页面上,可以看到,提交的任务被运行起来了:
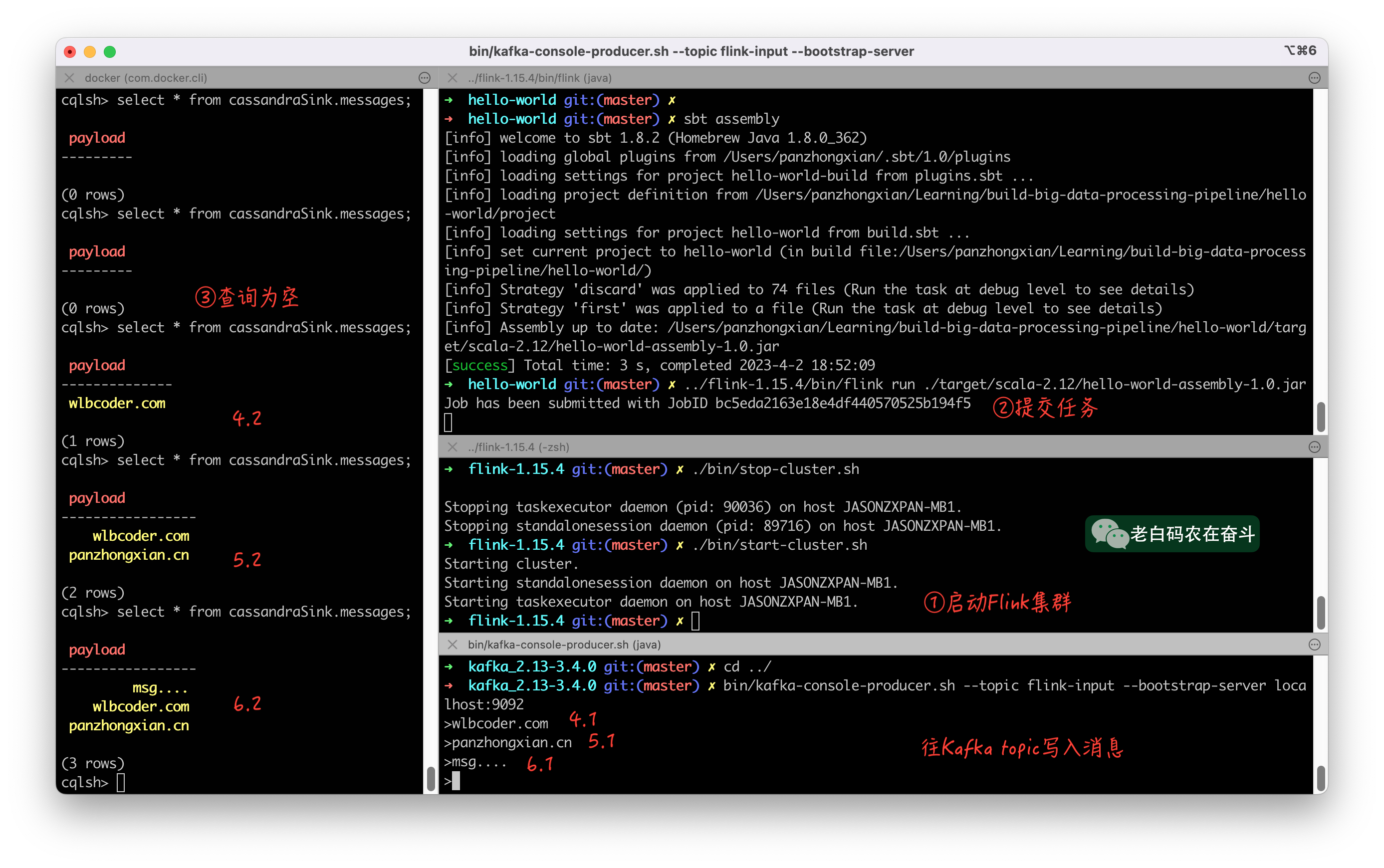
然后我们再往 Kafka topic 里边写入消息,写一条查一次,就可以观察到,会实时的被写入到了 Cassandra:
后续
本文简单介绍了大数据处理的基本流程、组件,用 Scala 构建出 .jar 文件并提交到 Flink 做流计算任务。
实际的项目,会比本文示例项目复杂得多。
在后续文章中,会进一步介绍 Flink DataStream API (窗口,Join),任务处理的并行执行,Scala 语言进阶等内容。