Oceanus 消费 TDBank/TubeMQ 多 Tid 遇到的问题与解决
潘忠显 / 2023-06-28
本文记录了在Oceanus上以Jar方式使用一个消费组,同时消费 TDBank 多个接口数据遇到的一些问题,以及解决方法。
1. 背景
TDBank(腾讯数据银行)是公司内的负责数据收集、分发、预处理的平台系统。其中有一部份功能是:业务侧部分日志数据通过 TDM / TGLOG 等方式落文件,TDAgent 会采集上报的,最终可写到消息队列 TubeMQ。
Oceanus 是公司内的实时计算平台。在 Oceanus 平台上,可以消费 TubeMQ 中的数据进行实时计算。
笔者在前段时间的工作中,需要在Oceanus上创建实时任务,从多个 Tdbank 业务下消费数据进行计算,而且每个业务下会同时消费多个接口数据。期间遇到了不少的问题,本文记录下问题内容、排查方式和解决方法。
任务所使用的开发和运行环境如下:
- Flink 1.15
- Scala 2.12.7
- sbt 1.8.2
- JAVA openjdk 1.8.0
2. 没有多 Tid 消费的示例
在天穹的 iWiki 使用Tube表 中,只有一个使用 flink-connector-tube 1.9 消费单个 Tid 的示例。直接使用 TubeSourceFunction 创建一个SourceFunction,在通过 env.addSource 将其添加成 Data Source。
//初始化TubeSourceFunction
SourceFunction<byte[]> sourceFunction =
new TubeSourceFunction(
masterAddress,
topic,
tids,
consumerGroup,
configuration
);
env.addSource(sourceFunction) //添加source
.flatMap(deserializer) //添加反序列化器
.addSink(new ConsoleSink()); //添加sink
而我需要使用 flink-connector-tube 1.15 去消费多个 Tid,即没有 1.15 SDK 的示例,也没有 1.9 SDK 消费多个 tid的示例,所以只能自己去探索一下。
尝试创建多个 TubeSourceFunction
因为一个消费组只会记录一组消费的状态,如果创建的多个 TubeSourceFunction,相当于并发的使用同一个消费组,无论是1.15 还是 1.9 这样都是不允许的。
如果这样使用,会在 Flink 拉起之后会立马抛异常退出。
尝试使用重载的 TubeSourceFunction
tube-connector 1.15 的 TubeSourceFunction 的构造函数有两个。
第一个是对应 1.9 示例中的消费单个 tid 的构造函数。与 1.9 的定义不同,这直接将 Deserializer 的 Schema 作为函数传入,直接 env.addSource 得到的将会是 DataStream[RowData] 而无需再做额外的反序列化:
public TubeSourceFunction(
String masterAddress,
String topic,
String consumerGroup,
DeserializationSchema<RowData> deserializationSchema,
String tids,
Configuration configuration
)
第二个构造函数如下,从输入参数可以猜测,可以传入多个 tid 以及多个 tid 对应的 DeserializationSchema——tidToDeserializationSchema,并且需要给每个 tid 传入一个路径用于后续的数据区分 —— tidToDataCollectionIds:
public TubeSourceFunction(
String masterAddress,
String topic,
String consumerGroup,
Map<String, DeserializationSchema<RowData>> tidToDeserializationSchema,
Map<String, Set<ObjectPath>> tidToDataCollectionIds,
String tids,
boolean isMultiplexing,
Configuration configuration
)
尝试使用第二个构造函数,去消费多个tid的数据,但是在这个过程中还会遇到新的问题。接下来解释下这些问题和解决。
3. 多 tid Source 数据分离
上边有提到,直接使用消费单个tid的TubeSourceFunction 添加的 Source 会得到一个 DataStream[RowData]。这个 RowData 是已经通过 DeserializerSchema 反序列化之后的,换句话说,可以直接通过 getString(pos) 或 getInt(pos) 等函数,直接根据接口定义的字段位置,从第pos个字段中,获取对应类型的值。
如何区分不同 tid 的数据
而通过第二个消费多个tid的 TubeSourceFunction 添加的Source同样会得到一个DataStream[RowData]那问题来了,从同一个流中,区分出不同的tid的数据呢?问了 天穹helper没有给找到具体的解释,只能自己的打印每一个RowData观察一下:

上边打印结果显示:该 Source 的所有非 RowData 只有两个元素,第一个是一个byte[],第二个是个字符串路径,这个路径恰好就是一个消费组ID + tidToDataCollectionIds传入的标签。因此,区分tid思路就是根据这个路径将数据分成不同的流。
自定义一个 ProcessFucntion 并重写其 processElement 函数,通过Flink 旁路输出的方式,得到多个流:
class MultipleTidSourceSplitter(
likeTag: OutputTag[Array[Byte]],
playTag: OutputTag[Array[Byte]])
extends ProcessFunction[RowData, RowData] {
override def processElement(
value: RowData,
ctx: ProcessFunction[RowData, RowData]#Context,
out: Collector[RowData]): Unit = {
val bytes = value.getBinary(0)
val path = value.getString(1).toString
if (path.endsWith("MapLikeFlow")) {
ctx.output(likeTag, bytes)
} else if (path.endsWith("MapEnjoyResultFlow")) {
ctx.output(playTag, bytes)
}
}
}
如何反序列化
上边区分出了不同数据的数据流,如何对 Array[Byte] 反序列化得到不同tid对应的RowData呢?光靠瞎猜和尝试是不行了,
这里要看 tube-connector 的源码看看这个结构到底是如何产生的,实际上上文提到的路径,也是在相同的位置塞进去的:
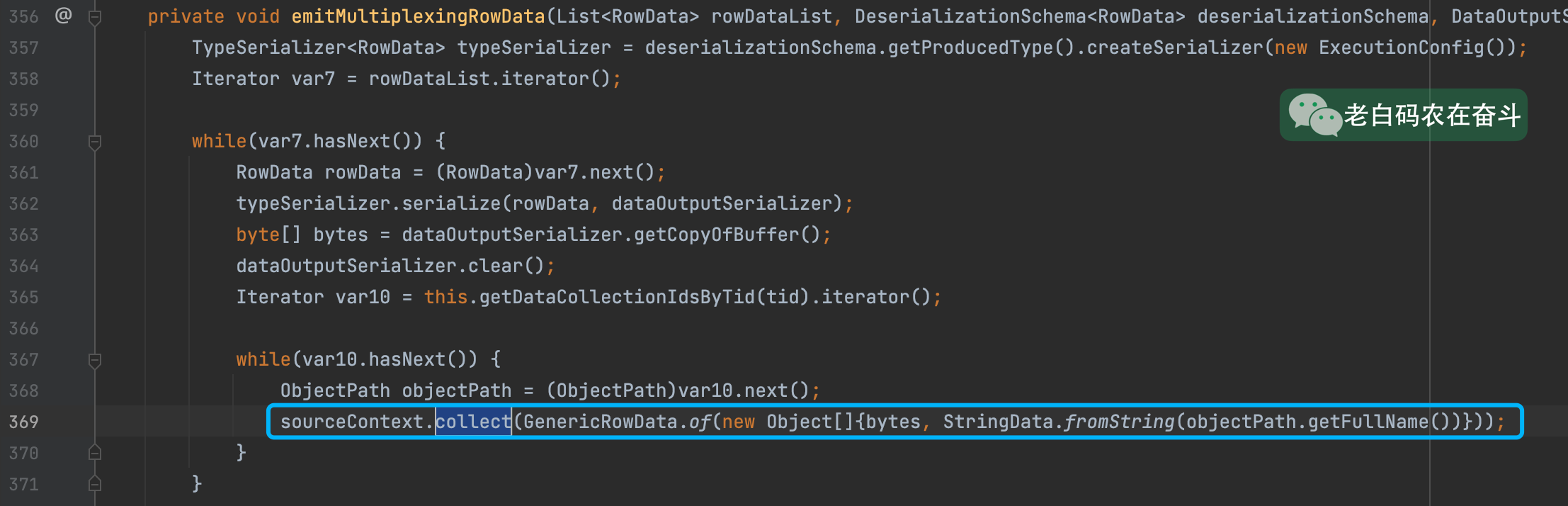
具体的这里 bytes 是 RowData +DataOutputSerializer 通过 DeserializationSchema 创建出来的 serializer 进行序列化得到的结果:
TypeSerializer<RowData> typeSerializer = deserializationSchema.getProducedType().createSerializer(new ExecutionConfig());
RowData rowData = (RowData)var7.next();
typeSerializer.serialize(rowData, dataOutputSerializer);
byte[] bytes = dataOutputSerializer.getCopyOfBuffer();
dataOutputSerializer.clear();
将上边的过程进行逆向的操作,便可以得到对应 bytes 的 RowData:
val typeSerializer = schema.getProducedType.createSerializer(new ExecutionConfig)
val deser = new DataInputDeserializer(bytes)
val rowData = typeSerializer.deserialize(deser)
4. 多Tid数据放大问题
前面的处理,已经能消费到多个 tid 的数据。但是在将程序部署运行之后,发现产生的数据数量远比数据源的真实数据数量多。
具体地,针对单个 tid 分别使用两种方式去消费,即使用单 tid 和多 tid 的 TubeSourceFunction 进行消费,发现后者产生的数据数量巨大。通过 Flink UI 也可以清楚看到这一点:
单 tid 消费方式输入输出流量放大 6 倍左右:

多 tid 消费方式输入输出流量放大 4000 倍左右

很明显如果仅仅是因为添加一个路径,是差不出这么大的差距的。这里联系了 TEG 实时湖仓研发组 的同学,确认了一下此处是有 Bug,进行了及时的修改并提供了 SNAPSHOT 版本,更新依赖之后解决此问题。
5. TDBank Header与Oceanus解析不一致问题
源数据有创建两个业务,以区分正式环境和测试环境,但是两个业务中的接口配置完全一样。之前在测试环境的数据源已经接入完成,没有问题,但是新起任务消费正式环境数据时,报了一个奇怪的错误:
Can’t find deserialization schema for tid 195430192
说他奇怪,是因为正式的消费和测试的消费tid一样,这里传入的都没有任何的数字形式的 tid:

也找到了抛出异常的函数位置,也就是说这个是从 tdMsg 里边获得 属性 tid 的时候得到了一个数字串:
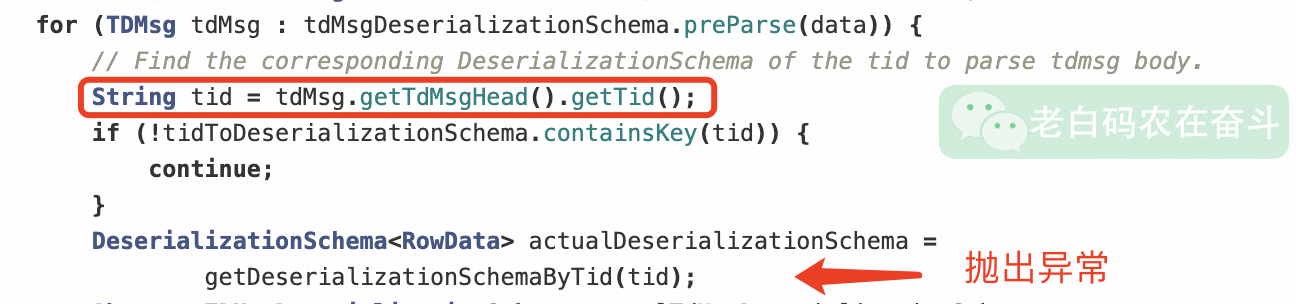
联系TEG 实时湖仓研发组 的同学帮忙排查,发现是。flink-format-tdmsg-csv 模块中,有个 TDMsgCsvUtils 会对 TDMsg Head 做解析,会一次取头中的 iname/id/tid 作为 tid:
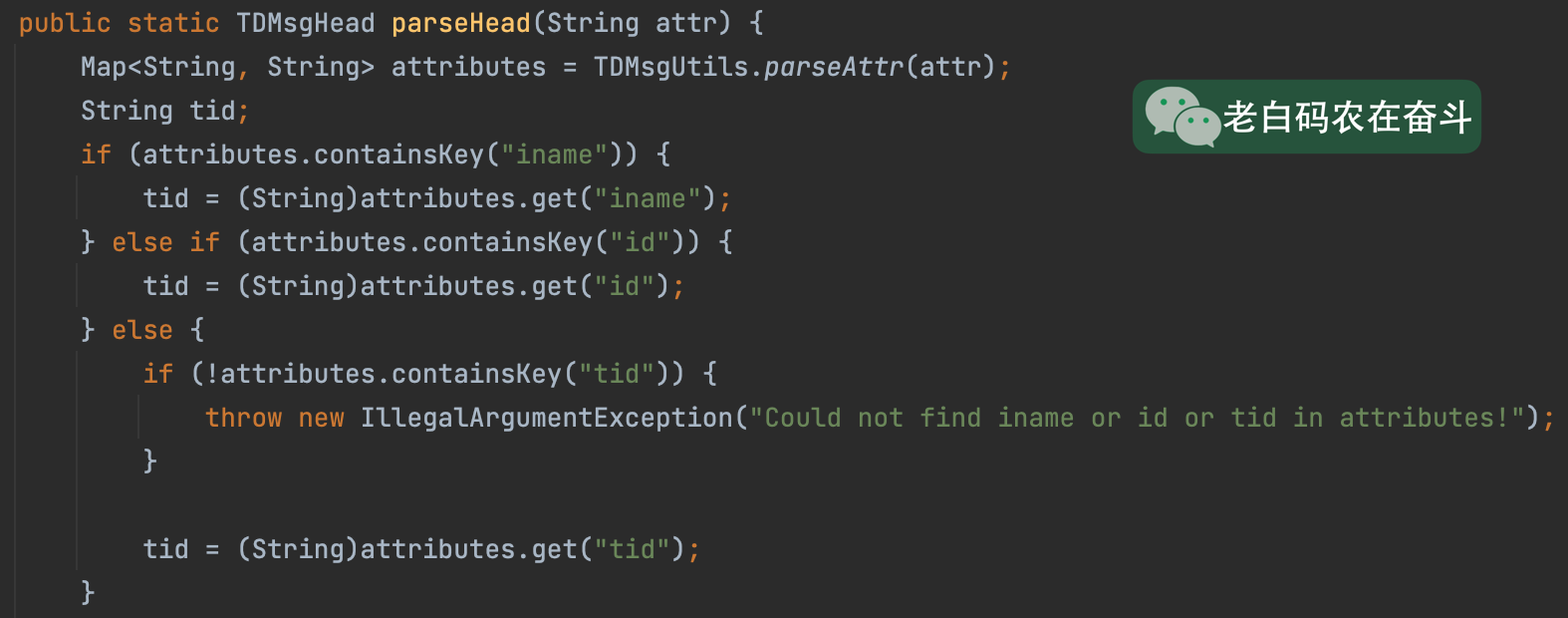
而查询TDBank上报的消息头中确实是有一个 id=195430192:

解决方法
经了解,上述数据源是业务侧同学自己上报的 tglog,也就是只有body的部分;tglog server 上有部署tdbank采集的agent,可能是不同版本或者不同配置的agent上报不同。显然这里的上报字段和 flink-format-tdmsg-csv 中对 tdbank 头的解析理解是不一致的。
实时湖仓的同学提出两种解决方案:
- 修改 flink-format-tdmsg-csv TDMsgCsvUtils,改掉 tid 的解析优先顺序
- 修改 flink-connector-tube TubeSourceFunc,在获取tid的位置直接从头中获得"tid"key 对应的值,而不是使用getTid函数
两者都需要拉去源码,然后生成 jar 后合到自己的代码中。但是前者是平台有提供依赖,做的修改可能带来冲突或者不生效。因此,直接修改 flink-connector-tube 源码。
具体地,这里 Scala 项目使用自定义 jar 的方法:
- 在 flink-connectors 项目中执行
mvn install,会产生 flink-connector-tube-1.15-tq-test-SNAPSHOT.jar - 将 build.sbt 中的对 flink-connector-tube 的依赖(libraryDependencies)去掉
- 在项目根目录中,放入 jar 文件
6. 其他问题
空字段解析问题
tdbank 是有混合数据源或者普通数据源。普通数据源如果以 \t 分割且如果前边的字段没有填写内容,会被 tube-connector 给处理掉,导致字段个数不一致的错误,不能正确消费到。入 TDW 是没有问题的。
代码填充前三个字段为空字符串:
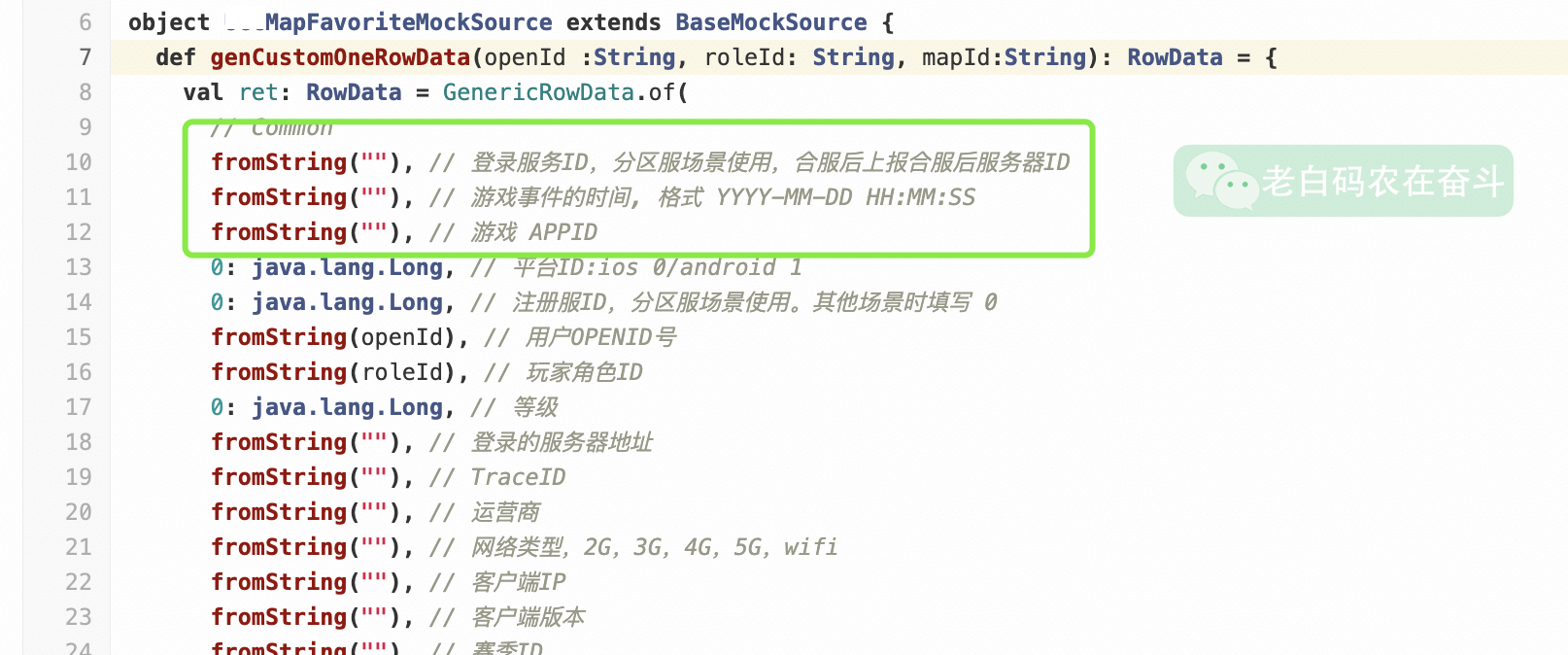
消费数据的开始是从两个 Long 字段开始的,前边的被掐掉了:

入TDW是没有问题的:
解决:上报者保证第一个字段别填空。
忽略异常数据
对于上边的异常数据,如果默认设置,会一直卡在上边的位置。因为 TubeSourceFunction 会记录消费的 TDBank的位置,消费到哪里没有正确的处理就任务退出,则不会记录到消费那条日志。
解决:可以在构建Desrializer的时候,将IgnoreError设置为true:
new TDMsgCsvFormatDeserializer.Builder(newTdmFormatInfo())
.setDelimiter('|')
.setIgnoreErrors(true)
.build())